Flink——项目:基于Flink的UAC实时流量异常监控告警模型
主要内容:
- 介绍项目:基于Flink的UAC实时流量异常监控告警模型
流量,是是系统的黄金指标,直观反映系统的运行状态。当流量突增(被爬虫爬取或攻击)或者突降(无法响应外部请求)时预示系统存在某种故障或异常行为。因此,流量异常检测对发现系统故障、维护系统稳定性十分重要。
1 需求
内部系统UAC的一次瘫痪,导致全员无法登陆公司内部云桌面和使用相关权限,严重影响正常办公,给公司造成较大损失。针对该情况,作为拥有其登陆日志的日志中心,将对UAC的流量进行监控,并及时发现异常流量、发出告警。
2 分析
2.1流量异常检测模型
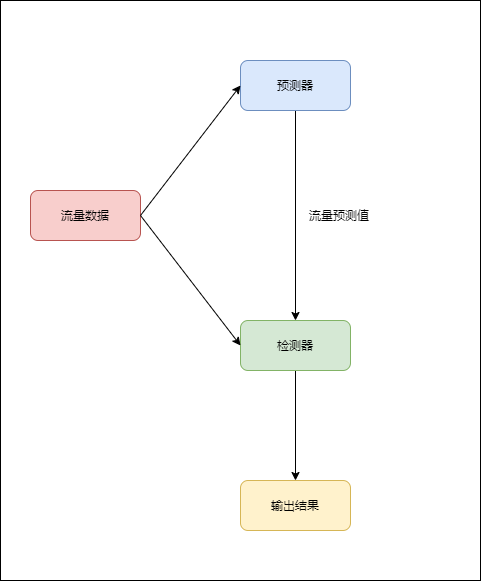
该模型分为两个阶段:
- 预测阶段:需要克服异常流量的影响,对流量进行精准预测
- 检测阶段:需要计算真实值与预测值之间的差异,当差异显著大于通常情况时,即可判定当前实际流量出现了异常
2.2 智能流量异常检测算法方案对比选择
2.2.1 预测算法:
算法1:移动平均
实现:使用当前窗口内w个数据的均值作为窗口内最后一个点的预测值。
移动平均算法简单地将窗口内数据的均值作为下一个点的预测值,没有考虑到窗口内的数据趋势,导致预测的趋势总是滞后于实际趋势,预测的结果不准确。
算法2:线性回归
实现:局部窗口内的线性表达式为y=kt+b,其中y为窗口内每个点的预测值,t为不同时刻,k,b为直线的斜率和截距。对于窗口内n个数据点 使用最小二乘法来最小化损失函数可以求得k,b参数,然后即可预测窗口内最后一个点的流量值。
线性回归方法容易受到异常点(突增、突降)的影响。线性回归的损失函数是二次函数,所以异常点带来的影响被放大,导致拟合的结果偏离理想结果。
算法3:鲁棒回归
鲁棒回归本质上来说也是线性回归,只是使用一次损失函数L1替换了二次损失函数L2,作用在于减弱异常点带给线性回归的影响。但由于L1不可导,没有确定的解析解,可以使用IRLS(Iterative Reweighted Least Squares) ,迭代加权最小二乘法,得到相对的最优解。这样在预测过程中就可以弱化突增、突降等异常点的影响,得到比较理想的预测结果。
2.2.2 检测算法
有了精准的预测结果,接下来需要根据预测结果检测流量是否出现异常。
算法1:残差(绝对残差)
实现:直接计算真实值与预测值之间的残差,得到真实值与预测值的绝对残差,以此来表征流量是够出现异常。流量预期值分别是200和20000情况下,
该方法没有考虑流量本身大小的因素,如残差为-100时,对于预期值是200的情况下,真实值是100就意味着系统很可能出现了故障导致无法处理请求;对于预期值是20000的情况下,真是是19900,可能只是正常的波动而已。所以使用基于残差的检测方法,需要我们针对不同的系统流量设置不同的阈值。
算法2:相对残差
计算:对流量的残差进行归一化处理,将真实值与预测值的差值再除以预测值作为结果。但此方法仍然存在一定的问题。例如大部分系统服务白天流量大,相对波动小,下跌10%可能意味着比较严重的问题;深夜流量小,相对波动大,下跌30%才有可能意味着系统存在故障。所以基于相对残差的检测方法也不能够设置统一的阈值来检测异常。
算法3:泊松分布
计算:流量是系统一段时间内接受到的请求次数,而泊松分布是描述单位时间内随机事件发生次数的概率分布,因此可以用泊松分布对流量进行建模。
不管是相对残差还是残差来设置统一的检测阈值都会有不适应的应用场景。该方法从概率的角度来设置恒定的检测阈值。系统大部分时间都处于正常状态,正常流量出现的概率远远大于异常流量,可以通过流量出现的概率大小来检测异常流量。
针对可能由于突增后保持一段时间后的降回正常值引发的误报,引入同比检测方法,将访问量与前几周的同一weekday相同时间点的访问量进行对比,利用3sigma对检测出的异常点进行再筛选。同样地,基于上述方法得到的异常点存在隐患是误报的出现,如果同期都是这样的情况一定程度上说明这是一种惯常的走向,3sigma一定程度也能缓解突增突降误报。
总结:
根据以上分析,本项目采取:
预测器:鲁邦回归算法
检测器:泊松分布+同比检测
3 方案
整体方案流程:
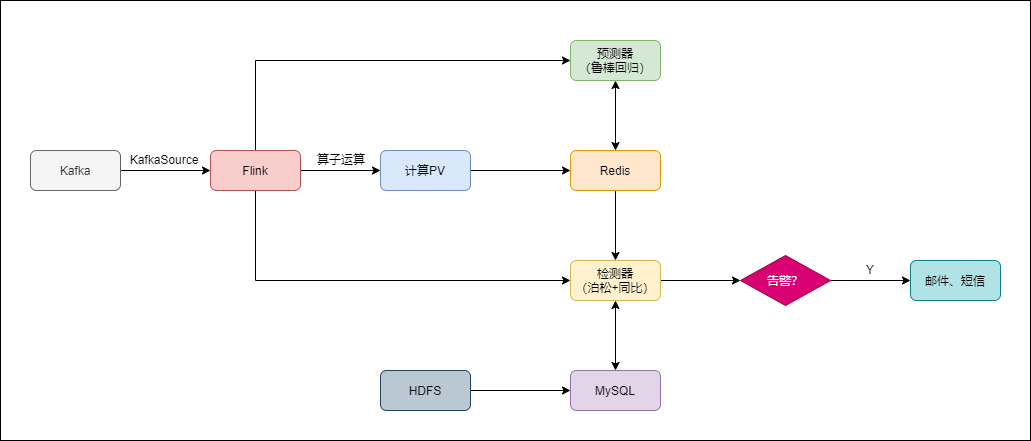
- Flink实时消费Kafka数据:Flink的Soure选择KafkaSource
- 记录当前PV:使用Flink DataStream API算子计算PV,并写入Redis。使用到map、filter、keyBy、sum、timeWindow等算子
- 检测当前PV值是否出现异常并告警:
- 从Redis取出当前时间的PV预测值
- 从MySQL取出历史前5周的、同weekday的、同一时间段的PV真实值(这部分值是通过HDFS上的离线数据统计出来的)
- 将上述步骤的结果作为参数传给检测器,经过泊松分布和同比检测算法检测,判断是否告警,若需要告警,则通过邮件或者短信的方式告知责任人
- 最后将实际值和预测值写入MySQL,当做历史数据,或为报表展示提供数据支撑
- 预测下一个时间间隔PV的预测值:
- 从Redis取出窗口长度的历史数据
- 传入鲁棒回归算法模型
- 预测出下一个时间间隔PV的预测值,并写入Redis
该方案中,需要多次读写MySQL,MySQL压力较大,后面会将其改为Hbase或者Redis。选择使用MySQL是由于后面在做可视化时,使用的是永洪科技的一站式大数据分析平台(国内)。
4 算法实现——Scala
4.1 预测器——鲁棒回归
/**
* 鲁棒回归算法实现
* IRLS(Iterative Reweighted Least Squares) 迭代加权最小二乘法
*
* @param X:待拟合窗口中的序列,如果窗口为20,X_则为1,2,3...20
* @param y:待拟合窗口中的访问量
* @return
*/
def IRLS(X: DenseMatrix[Double], y: DenseVector[Double]): Tuple2[DenseVector[Double], ArrayBuffer[Double]] = {
if (y.toArray.length != WINDOW_SIZE || y.toArray.length == 0) {
println("请提供与窗口长度一致的数据量")
sys.exit(-1)
} else {
val err = ArrayBuffer[Double]() // 迭代误差,欧式距离
val W = DenseMatrix.eye[Double](X.rows) //W权重 初始值 单位阵
var beta_old = DenseVector.ones[Double](X.cols) //beta 初始值
var beta_new = inv(X.t * W * X)*(X.t * W * y) //beta 更新值
// 根据迭代方式求得相对优的线性参数
for (iter <- 0 until ITERATION) {
if (norm((X * beta_old) - (X * beta_new)) > EPSILON) {
for (i <- 0 until X.rows) {
val W_i = abs(y(i) - (X(i, ::) * beta_new))
val max_ = List(0.0001, W_i).max // 0.0001 避免除数为0的情况
W(i, i) = 1.0 / max_
}
beta_old = beta_new.copy
beta_new = inv(X.t * W * X) * (X.t * W * y)
err += norm(X * beta_old - X * beta_new)
} else {
if (iter == ITERATION - 1 && err.reverse(0) > EPSILON) {
println("当前误差:" + err.reverse(0) + "达到了最大循环次数,如果您对当前的误差不满意,请增大循环次数!")
}
}
}
val result = (beta_new, err): Tuple2[DenseVector[Double], ArrayBuffer[Double]]
result
}
}
/**
*
* @param y
* @return
*/
def predict(y: DenseVector[Double]): Double = {
if (y.toArray.length != windowSize || y.toArray.length == 0) {
println("请提供与窗口长度一致的数据量!")
}
val X = DenseMatrix.tabulate(windowSize, 2) {
case (i, j) => if (j == 0) {
i.toDouble + 1
} else {
1.toDouble
}
}
val result = IRLS(X, y)
result._1(0) * (windowSize + 1) + result._1(1)
}
4.2 检测器——泊松分布、同比检测
/**
*
* @param X
* @param valuePredicted
* @param threshold
* @return
*/
def algorithmDetect(X: DenseVector[Double], valuePredicted: Double, threshold: Int = 10): Boolean = {
val len = X.length - 2
val meanVal = mean(X(0 to len))
val stdVal = stddev(X(0 to len))
if (abs(X(-1) - valuePredicted) / sqrt(valuePredicted) > threshold // 泊松分布
&& abs(X(-1) - meanVal) / stdVal > 3 // 同比检测
) {
true
} else {
false
}
}
4.3 主程序
主程序部分参考PVUV的计算,另外 需要创建几个辅助类工具:Redis、Mysql等。
4 总结
一方面,基于鲁棒回归的预测算法,可以不受异常点的影响,精准地预测流量水位值;另一方面,基于泊松分布、同步检测的检测算法,可以从概率的角度对流量建模,能够使用简单的恒定阈值来精准地检测流量异常。
需要思考:
- 在设置告警条件时,还需要结合具体业务来进一步确定是否属于误报
- 项目中涉及到多个参数的调优如:
- 窗口长度
- 时间间隔
- 鲁棒回归中:迭代次数、误差大小
- 泊松分布、同比检测中:阈值等