Kafka——如何理解Kafka的“快”?
据了解,Kafka吞吐量峰值每秒百万,就算在内存个CPU都不高的情况下,最高可达每秒十万,并且还能做到持久化存储。Kafka如此高吞吐率的原因是什么?
1 应用层面的优化
-
使用批次:producer和consumer都使用批次进行读写——避免在网络上频繁传输单个消息带来的延迟和宽带开销;
-
高效压缩:将多条消息压缩在一起,而不是分别压缩每条消息,牺牲部分CPU性能换取IO吞吐量的提升。自带压缩方式:
GZIP和Snappy。消息在写入时进行压缩,消息在传输和存储均为压缩状态,只有在消费时由consumer解压缩——减少网络传输压力; -
水平扩展:分区——多分区同时读写。
-
高效的存储结构:topic、partition、segment、索引文件、稀疏存储等。
2 写得快
- 顺序写磁盘:大多数传统的数据系统都使用内存存储数据,因其提供了极低的延迟。但由于价格昂贵,持久化等问题,Kafka将消息持久化到磁盘。磁盘读写的快慢,取决于如何使用它,即随机写或顺序写。随机写的寻址过程是一个“机械动作”(相比于内存),也最耗时。为了规避随机写带来的消耗,Kafka就使用顺序写磁盘:每条消息都被append到分区log文件。顺序写可达
400M/S,随机写每秒几十几百K。 MMap(Memory Mapped Files):内存映射文件,即将一个文件或其他对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址中一段虚拟地址的一一映射关系。作用:将磁盘文件映射到进程的内存,用户通过修改内存就能修改磁盘文件,即完成了对文件的操作,而不必再调用read、write等系统调用函数。
3 读得快
-
Page Cache:kafka 在设计时以 page cache 为中心, 充分利用操作系统提供的 page cache , 而不是在 JVM 内存中维护对象。借力于Linux内核的Page Cache,不(显式)用内存,胜用内存——空中接力。
-
零拷贝:数据直接在内核空间完成输入和输出,不需要拷贝到用户空间。Kafka写数据前,先写到进程的内存空间。零拷贝并非不需要拷贝,而是减少不必要的拷贝,主要指在内核空间和用户空间之间的拷贝,进而提高效率。从磁盘获取数据并通过网络发送数据时,一般流程:

-
操作系统从磁盘将数据Copy(
DMA Copy)到内核空间缓冲区(Kernel Buffer); -
应用程序从内核空间缓冲区(
Kernel Buffer)将数据Copy(CPU Copy)到用户空间缓冲区(User Buffer); -
应用程序从用户空间缓冲区(
User Buffer)将数据Copy(CPU Copy)到Socket缓冲区(Socket Buffer); -
操作系统从Socket缓冲区(
Socket Buffer)将数据Copy(DMA Copy)到网卡(NIC Buffer),由网卡进行网络传输。其中涉及4次copy、4次上下文切换和2次CPU中断,而第2次和第3次的Copy只是把数据Copy到用户空间又原封不动地Copy回来,因此带来了2次CPU Copy和2次上下文切换,这是完全没必要的。零拷贝技术就是为了优化掉这2次不必要的Copy。
sendFileLinux内核2.1引入
sendFile系统调用:在内核空间把数据从内核缓冲区直接复制到Socket缓冲区,从而减少不必要的Copy和上下文切换。引入sendFile后,上述流程简化为:
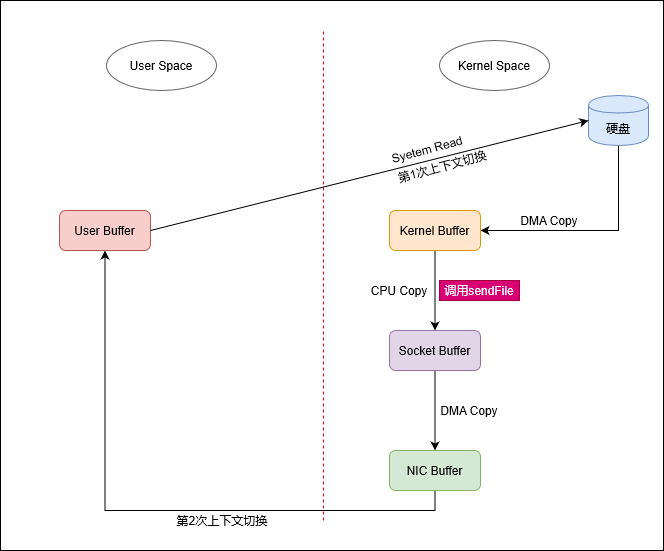
-
操作系统将数据从磁盘Copy(
DMA Copy)到内核空间缓冲区(Kernel Buffer); -
应用程序通过
sendFile,在内核空间,从内核空间缓冲区(Kernel Buffer)将数据Copy(CPU Copy)到Socket缓冲区(Socket Buffer); -
操作系统从Socket缓冲区(
Socket Buffer)将数据Copy(DMA Copy)到网卡(NIC Buffer),由网卡进行网络传输。可见,利用
sendFile系统调用后,可以将4次Copy减少到3次,4次上下文切换减少到2次,2次CPU中断减少到1次。